- Home ›
- Java入門 ›
- Javaソースファイルのエンコーディング ›
- HERE
ネイティブコードからUnicodeへ変換(native2ascii)
ここまで見てきた通りプログラムの中にASCII文字以外の日本語などが含まれている場合、保存された文字コードに合わせてコンパイル時に文字コードを指定する必要があります。
そこでソースコードの中の日本語の部分を全てUnicode コード(¥udddd 表記)に変換することによって、ソースコードから日本語の部分を取り除くことができます。その結果としてどのような環境であってもソースファイルの文字コードを気にすることなくコンパイルを行うことができます。
日本語を一つ一つUnicodeに変換することは大変ですが、その為のツールとしてnative2asciiが用意されています。使い方は次のようになります。
native2ascii 元のファイル 変換後のファイル
変換元のファイルに含まれる日本語部分をUnicodeコードに変換し、変換後のファイル名として出力します。ここで変換元のファイルが環境毎の決まっているデフォルトのエンコーディング以外で保存されている場合は、次のように文字コードを指定して下さい。
native2ascii -encoding エンコーディング名 元のファイル 変換後のファイル
どのように変換されるのかは次のサンプルを参照して下さい。
サンプル
では実際に試してみます。
class JSample3_1{
public static void main(String args[]){
System.out.println("こんにちは");
System.out.println("お元気ですか");
}
}
上記を文字コードにUTF-8を指定して保存します。そして次のようにnative2asciiを使って変換します。
native2ascii -encoding UTF-8 JSample3_1.java JSample3_2.java
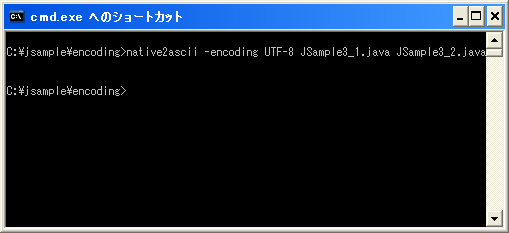
では変換されたJSample3_2.javaを確認してみます。
class JSample3_1{
public static void main(String args[]){
System.out.println("¥u3053¥u3093¥u306b¥u3061¥u306f");
System.out.println("¥u304a¥u5143¥u6c17¥u3067¥u3059¥u304b");
}
}
変換前のソースファイルの中に含まれていた日本語の部分が¥udddd 表記に置き換えられています。ではこのファイルのコンパイルを行ってみます。(ファイル名が変更されていますので、クラス名もJSample3_1からJSample3_2に変更しておく必要があります)。
javac JSample3_2.java
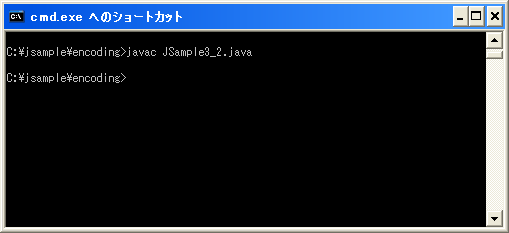
ソースファイル内にはASCIIとUnicodeコードしか存在しませんので保存された文字コードを気にせずコンパイルすることができます。では実行も行ってみます。
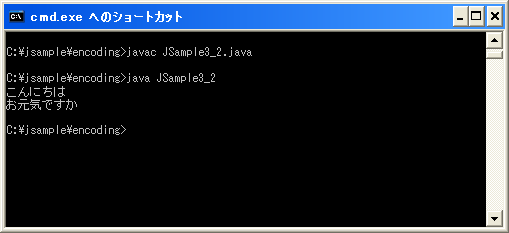
実行結果は変換前でも変換後でも変わりはありません。
可読性が悪くなりますので通常はこのような変換を行う必要はないかもしれませんが、様々な環境でコンパイルされるソースコードを配布したい場合などには便利かもしれません。
元に戻す
同じツールを使うことでUnicode コード(¥udddd 表記)形式で記述されたものを日本語に戻すことができます。次のように行います。
native2ascii -reverse 元のファイル 変換後のファイル
元のファイルに含まれているUnicode コード(¥udddd 表記)形式で記述された部分を日本語に変換し、ファイルとして出力します。この時変換後のファイルの文字コードを指定することができませんでしたので環境毎のデフォルトエンコーディングを使って変換されます。
( Written by Tatsuo Ikura )
