- Home ›
- Java正規表現の使い方 ›
- いずれかの文字に一致(文字クラス) ›
- HERE
定義済みの文字クラス
文字クラスでは比較的よく利用される組み合わせがあります。例えば数字を表す"[0-9]"などです。このような比較的よく利用される文字クラスには略記が定義されています。ここでは文字クラスの略記法について確認します。
数字を表す"¥d"と"¥D"
"¥d"は数字を表す略記法です。文字クラスの"[0-9]"に該当します。
"¥d" "[¥d]" "[0-9]"
上記は0~9のいずれかの文字にマッチします。"¥d"は文字クラスを表すブラケット[]の外側でも記述できますが、文字クラスの中の1つの候補としてブラケット内にも記述することが出来ます。
"[¥dabc]"
上記は"0~9"と"a"、"b"のいずれかの文字にマッチします。
また"¥D"は数字以外を表す略記法です。文字クラスの"[^0-9]"または"[^¥d]"に該当します。
"¥D" "[¥D]" "[^¥d]" "[^0-9]"
上記は0~9以外のいずれかの文字にマッチします。
任意の桁の数字にマッチするパターンは次のように記述することができます。
"[¥d+]"
単語構成文字を表す"¥w"と"¥W"
"¥w"は単語構成文字を表す略記法です。文字クラスの"[0-9a-zA-Z_]"に該当します。アルファベットのaからzとAからZ、数字の0から9、そして"_"の集合です。
"¥w" "[¥w]" "[a-zA-Z0-9_]"
上記は0~9、a~z、A~Z、"_"のいずれかの文字にマッチします。"¥w"は文字クラスを表すブラケット[]の外側でも記述できますが、文字クラスの中の1つの候補としてブラケット内にも記述することが出来ます。
また"¥W"は単語構成文字以外を表す略記法です。文字クラスの"[^0-9a-zA-Z_]"または"[^¥w]"に該当します。
"¥W" "[¥W]" "[^¥w]" "[^a-zA-Z0-9_]"
上記は単語構成文字以外の全ての文字にマッチします。
任意の桁の単語構成文字からなら文字列にマッチするパターンは次のように記述することができます。
"[¥w+]"
空白を表す"¥s"と"¥S"
"¥s"は空白を表す略記法です。文字クラスの"[ ¥t¥n¥x0B¥f¥r]"に該当します。空白" "、タブ("¥t")、改行("¥n")、垂直タブ("¥x0B")、用紙送り文字("¥f")、キャリッジリターン("¥r")の集合です。
"¥s" "[¥s]" "[ ¥t¥n¥x0B¥f¥r]"
上記は空白と扱われる各文字ののいずれかの文字にマッチします。"¥s"は文字クラスを表すブラケット[]の外側でも記述できますが、文字クラスの中の1つの候補としてブラケット内にも記述することが出来ます。
また"¥S"は空白文字以外を表す略記法です。文字クラスの"[^ ¥t¥n¥x0B¥f¥r]"または"[^¥s]"に該当します。
"¥S" "[¥S]" "[^¥s]" "[^ ¥t¥n¥x0B¥f¥r]"
上記は空白文字以外の全ての文字にマッチします。
"¥s"を使い任意の連続する空白文字に文字にマッチするパターンは次のように記述できます。
"[¥s+]"
POSIX 文字クラス
定義済みのクラス以外にPOSIX 文字クラスと呼ばれるものも用意されています。次のようなものがあります。
¥p{Lower} 小文字の英字:[a-z]
¥p{Upper} 大文字の英字: [A-Z]
¥p{ASCII} すべての ASCII 文字: [¥x00-¥x7F]
¥p{Alpha} 英字: [¥p{Lower}¥p{Upper}]
¥p{Digit} 10 進数字: [0-9]
¥p{Alnum} 英数字: [¥p{Alpha}¥p{Digit}]
¥p{Punct} 句読文字:!"#$%&'()*+,-./:;<=>?@[¥]^_`{|}~ のいずれか
¥p{Graph} 表示できる文字:[¥p{Alnum}¥p{Punct}]
¥p{Print} プリント可能文字:[¥p{Graph}¥x20]
¥p{Blank} 空白またはタブ:[ ¥t]
¥p{Cntrl} 制御文字:[¥x00-¥x1F¥x7F]
¥p{XDigit} 16 進数字:[0-9a-fA-F]
¥p{Space} 空白文字:[ ¥t¥n¥x0B¥f¥r]
例えば"¥w"と記述する代わりに"¥p{Space}"と記述しても同じです。
ただしこのPOSIX文字クラスはUS-ASCIIのみで使用できます。
サンプルプログラム
では実際に試してみます。
import java.util.regex.Pattern;
import java.util.regex.Matcher;
class JSample5_1{
public static void main(String args[]){
String str1 = "example.jp";
String str2 = "example.co.jp";
String str3 = "example.com";
String regex = "¥¥w+(¥¥.¥¥w)*¥¥.jp";
Pattern p = Pattern.compile(regex);
System.out.println("パターン : " + regex);
check(p, str1);
check(p, str2);
check(p, str3);
}
private static void check(Pattern p, String target){
Matcher m = p.matcher(target);
if (m.find()){
System.out.println("○ " + target);
}else{
System.out.println("× " + target);
}
}
}
ではコンパイルを行った上で実行してみます。
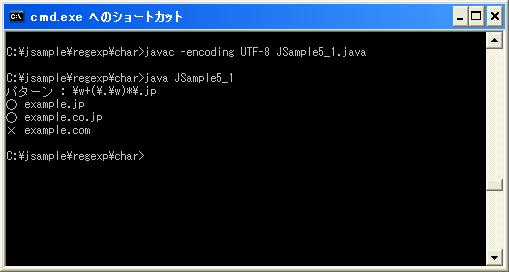
エスケープがされているので分かりにくいですが"¥¥w+(¥¥.¥¥w)*¥¥.jp"は"¥w"が1回以上続き、文字の"."か"¥w"のいずれかが0回以上続き、さらに文字の"."と文字列の"jp"が続くパターンです。
( Written by Tatsuo Ikura )
